前言
本文旨在介绍Elasticsearch,包括:
- ES基本知识,如数据类型,倒排索引
- ES基本查询,如Term Level Query(精准匹配)和Full text Query(模糊匹配)
如果你有如下疑问:
- ES能做什么?
- ES为什么这么快?
- ES查询有几种?都应该怎么写?
那这篇文章肯定能帮助到你。
ES数据类型
string
string分两种,text和keyword。
text类型储存,当我们不去特殊定义它的分词器,那么ES就会使用默认的分词器standard。
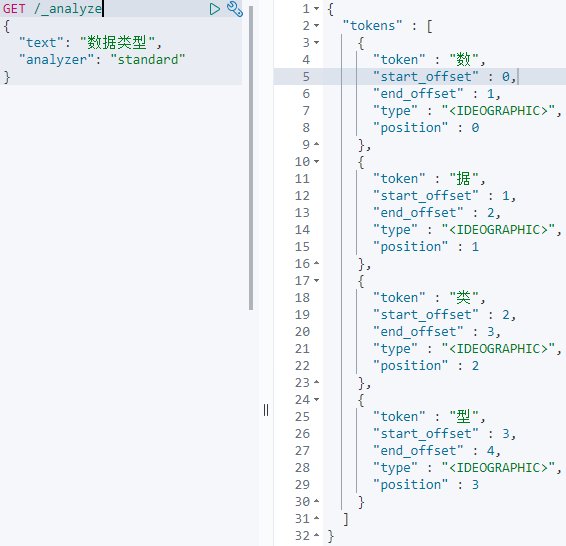
而ES搜索的时候搜的是倒排索引,也就是分词后的字符串,这就意味着,如果使用text类型去储存你本不想分词的string类型,你在查询的时候,查询结果将违背你的预期:
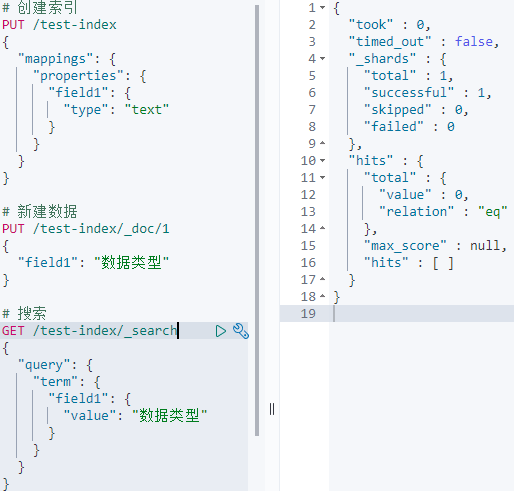
其中term查询本应该是精准匹配,按理说能查到完整字符串,但因为field1是text类型,所以搜索不到。这时如果搜索单独的分词比如“数”,是可以搜到的。
要想ES不分词,就要使用keyword类型:
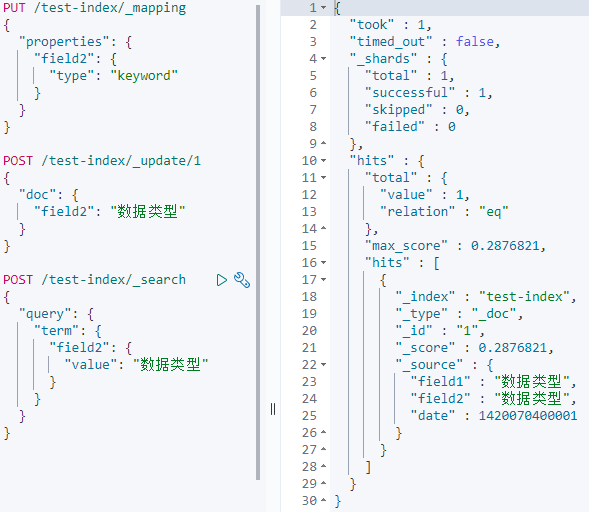
小结:text分词,keyword不分词。
date
ES的date类型允许我们规定格式,可以使用的格式有:
- yyyy-MM-dd HH:mm:ss
- yyyy-MM-dd
- epoch_millis(毫秒值)
一旦我们规定了格式,如果新增数据不符合这个格式,ES将会报错mapper_parsing_exception。
复杂类型
ES有3个复杂类型:Array、object、nested。
Array:在Elasticsearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值都必须具有相同的数据类型。
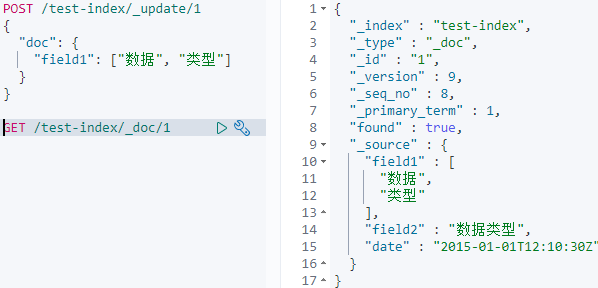
Object:这个要注意object类型的字段,也可以有多个值,形成List<object>的数据结构,而且object不允许彼此独立地索引查询

可以看到本来我们只想查name是cg,age是1的数据,但是搜出了两个,这就是因为object不允许彼此独立地索引查询;要想objcet能被独立索引,就需要netest类型。
Nested类型:需要建立对象数组的索引并保持数组中每个对象的独立性,则应使用nested数据类型而不是object数据类型。在内部,每个嵌套的对象可以被独立的查询。
Geo地理位置
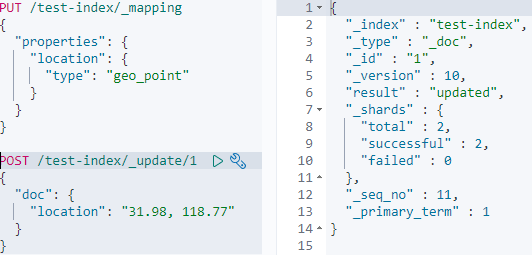
Geo-point的格式有好几种,查询时可以按照距离查附近的数据,具体可以看看官方文档。
倒排索引
上回书提到了倒排索引,它是ES能快速查找的根基,这回就讲讲什么是倒排索引。
假如有个博客系统,如果用MySQl的话大概会这么存储:
| Id | Author | Title | Content |
|---|---|---|---|
| 1 | cg | Es hands on | 学习ES |
| 2 | cg | Mysql hands on | 快乐学习MySQL |
这样用Id或者Title是可以快速查找到相应的博客,因为Id、Title是很方便建立索引的。但当搜索Content却不能高效查询,因为Content是没法建立索引的。倒排索引就是把Content分词,然后用分词快速查询Id来建立索引:
| Token | id=1 | id = 2 |
|---|---|---|
| 学习 | T | T |
| 快乐 | F | T |
| ES | T | F |
| MySQL | F | T |
倒排序索引包含两个部分:
- 单词词典:记录所有文档单词,记录单词到倒排列表的关联关系
- 倒排列表:记录单词与对应文档结合,由倒排索引项组成
倒排索引项:
- 文档
- 词频 TF - 单词在文档中出现的次数,用于相关性评分
- 位置(Position)- 单词在文档中分词的位置,用于phrase query
- 偏移(Offset)- 记录单词开始结束的位置,实现高亮显示
- 偏移(Offset)- 记录单词开始结束的位置,实现高亮显示
比如以Token“学习”为例:
| Token | doc_Id | TF | Position | Offset |
|---|---|---|---|---|
| 学习 | 1 | 1 | 0 | <0,2> |
| 2 | 1 | 1 | <2,4> |
搜索的过程:
- 先分词,得到Token(比如“快乐学习”会被分为“快乐”,“学习”)
- 然后去倒排索引中进行匹配(“快乐学习”两个id都会匹配到,但是文档2评分回避1高,因为2匹配了两个Token)
可以看到匹配不匹配的到和分词有很大的关系,在ES中是通过Analyzer来分词的。
Analyzer由三部分组成:
- Character Filters:首先,字符串按顺序通过每个字符过滤器 。他们的任务是在分词前整理字符串。比如一个字符过滤器可以用来去掉HTML,或者将 & 转化成 and。
- Tokenizer:其次,字符串被 分词器 分为单个的词条。比如一个whitespace分词器遇到空格和标点的时候,可能会将文本拆分成词条:
- Token Filters:最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条,例如,lowercase token filter 小写化(将ES转为es)、stop token filter 删除词条(例如, 像 a, and, the 等无用词),或者synonym token filter 增加词条(例如,像 jump 和 leap 这种同义词)。
自定义Analyzer

Full text queries
ik分词
- ik_max_word:会将文本做最细粒度的拆分,比如会将“系统学习ES”拆分为“系统学,系统,学习,es”,会穷尽各种可能的组合,适合 Term Query;
- ik_smart: 会做最粗粒度的拆分,比如会将“系统学习ES”拆分为“系统,学习,es”,适合 Phrase 查询。
一般情况下,为了提高搜索的效果,需要这两种分词器配合使用。既建索引时用 ik_max_word 尽可能多的分词,而搜索时用 ik_smart 尽可能提高匹配准度,让用户的搜索尽可能的准确。比如一个常见的场景,就是搜索”进口红酒”的时候,尽可能的不要出现口红相关商品或者让口红不要排在前面。
Full text queries – match
先建个新字段:
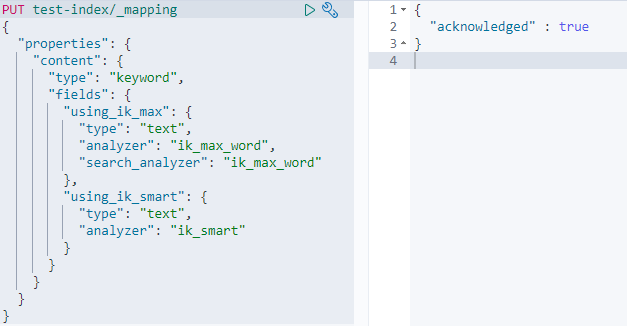
注意这个字段本身是keyword类型,但又有两个text类型的子field,分别配置了不同的分词器,相比粗暴的用不同的字段去实现配置不同的分词器而言,一个字段配置多个分词器在数据的存储和操作上方便许多,只用储存一个字段,即可得到不同的分词效果。
填充一点数据:

对content默认的keyword进行检索:

原因之前也说过,很简单,因为keyword是不会分词的。
对content做了分词的子字段进行检索:

ik_smart会把“真有意思”分成一个词,所以第二个查询只能查到前两个文档。
指定operator参数:

还行,有意思被分词为还行、有意思两个token;不指定operator的话默认是or,所以10和11能被搜到;
指定成and的话则需要文档同时包含这两个token,所以没有结果。
Full text queries – match_phrase
match_phrase
match_phrase 会将检索关键词分词。match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的。

slop参数

slop参数表示token之间的位置距离容差值,上面是1表示token之前可以跳一个token,所以上面可以检索出10和11。
Full text queries – match_phrase_prefix
与match_phrase查询类似,但是会对最后一个Token在倒排序索引列表中进行通配符搜索。Token的模糊匹配数控制:max_expansions默认值为50;
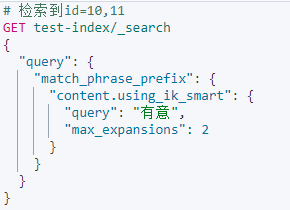
因为ik_smart会把文档12中的真有意思分成一个词,所以只能检索到10和11。
到此,我们已经学习了 Full text queries最常用的3种查询:
matchquery:用于执行全文查询的标准查询,包括模糊匹配和短语或接近查询。重要参数:控制Token之间的布尔关系:operator:or/andmatch_phrasequery:与match查询类似,但用于匹配确切的短语或单词接近匹配。重要参数:Token之间的位置距离:slop 参数match_phrase_prefixquery:与match_phrase查询类似,但是会对最后一个Token在倒排序索引列表中进行通配符搜索。重要参数:模糊匹配数控制:max_expansions 默认值50,最小值为1
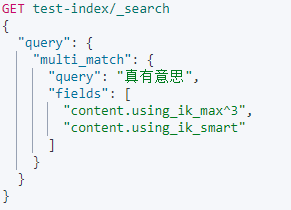
Full text queries – multi_match
multi_match就是match的多字段版本,需要注意的是,多个fields之间的查询关系是or。

字段^数字:表示增强该字段(权重影响相关性评分):
Full text queries – query_string
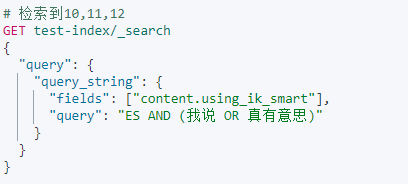
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和multi_match一样,支持多字段搜索。
Full text queries – simple_query_string
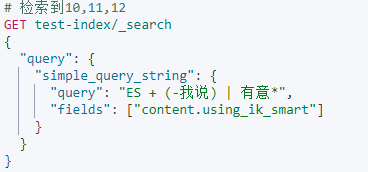
类似于query_string ,但是会忽略错误的语法,永远不会引发异常,并且会丢弃查询的无效部分。
simple_query_string支持以下特殊字符:
- + 表示与运算,相当于query_string 的 AND
- | 表示或运算,相当于query_string 的 OR
- - 取反单个令牌,相当于query_string 的 NOT
- ”” 表示对检索词进行 match_phrase query
- * 字词末尾表示前缀查询 match_phrase_prefix
Term level Queries
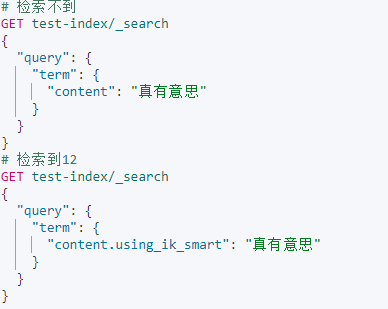
Term level queries - term
Term查询和Match区别在于Term不会对被检索的字段分词;Term一般用于检索不会被分词的字段,主要是类型为:integer、keyword、boolean 的字段。
- 检索会被分词的字段,match语句与term语句区别较大。
- 检索不会分词的字段:match语句与term语句效果一致。
Term level queries - terms
相当于MySQL的in:

terms lookup
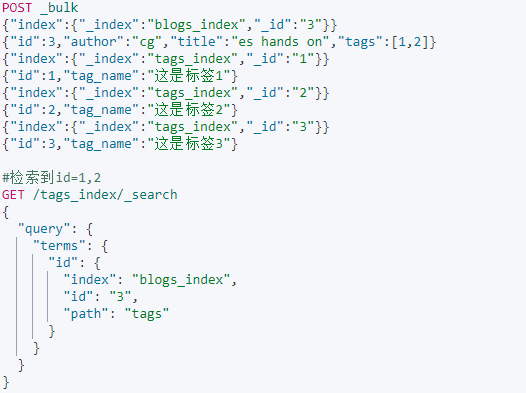
相当于select * from tags_index where id in (select tag from blogs_index where id = 3)
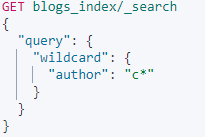
Term level queries - wildcard
- 通配符
*:匹配任何字符序列(包括空字符) - 占位符
?:匹配任何单个字符。
类似MySQL的like,为了防止极慢的通配符查询,通配符术语不应以通配符*或?开头。
Term level queries - prefix
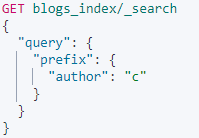
和上面wildcardc*等价。
Term level queries - fuzzy
模糊查询使用基于Levenshtein编辑距离的相似度。是一种误拼写时的fuzzy模糊搜索技术,用于搜索的时候可能输入的文本会出现误拼写的情况。比如输入”hands”,这时候也要匹配到“hansd”
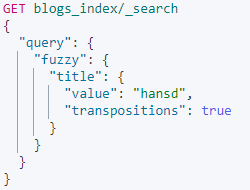
- fuzziness:最大编辑距离【一个字符串要与另一个字符串相同必须更改的一个字符数】。默认为AUTO。
- prefix_length:不会被“模糊化”的初始字符数。这有助于减少必须检查的术语数量。默认为0。
- max_expansions:fuzzy查询将扩展到的最大术语数。默认为50。
- transpositions:是否支持模糊转置(ab→ ba)。默认值为false。
如果prefix_length将设置为0,并且max_expansions将设置为很高的数字,则此查询可能会很繁琐。这可能会导致索引中的每一项都受到检查!
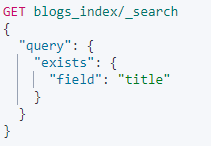
Term level queries - exists
- 查找指定字段包含任何非空值(不是
null也不是[ ])的文档。
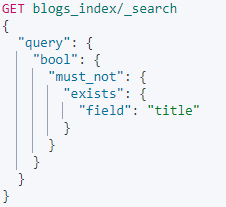
- 反过来,查询为null的字段,可以组合:must_not + exists
Term level queries - terms_set
terms_set和terms差不多,但是可以指定要匹配的数量:
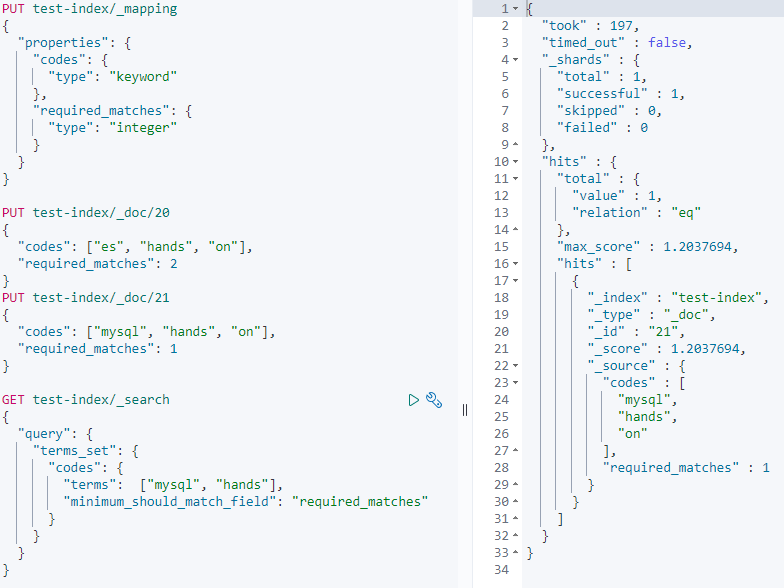
如果每个文档需要的required_matches值都相同时,那就没必要用这个里,直接用match就行:

Term level queries - regexp query
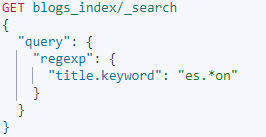
注意:regexp查询的性能在很大程度上取决于所选的正则表达式。.*都很慢,而且使用环视正则表达式也很慢。如果可以的话,应在正则表达式开始之前尝试使用长前缀 .
Bool Query
Bool Query把其它的Query都组合了起来,可以说是最重要的查询了。
在讲Bool Query之前,ES有个关键的东西一直没讲,那就是Query Context和Filter Context。
ES中一个重要的概念就是得分,用ES不仅是因为它快,还因为ES能做到MySQL做不到的 – 返回匹配程度,搜的结果有一个得分,得分越高,就表示文档越匹配;那就有个问题,有的查询需要看得分,有的不一定需要,这就区分除了两种查询:
- Filter Context:只看文档是否匹配(yes/no),不看得分。类似MySQL里的where条件查询,MySQL是没法返回模糊的结果的。
- yes/no 搜索
- 精准匹配(数字,范围,keyword)
- Filter Context的搜索结果会被自动缓存
- Query Context:计算得分,返回结果的得分展示了文档的匹配程度。
- 模糊搜索(文档有匹配度)
- full-text搜索
Bool Query是由而且仅由下面一个或多个字句构建的:
must:必须匹配,计算得分,类似MySQL的and;should:应该匹配,可配置最小匹配数,计算得分,类似MySQL的or;filter:必须匹配,不计算得分;must_not:不应该匹配,不计算得分;
其它注意事项:
- 以上4种查询的子句,只支持
Full text queries和Term level queries和Bool query(可以套娃); must、should是 query contextfilter、must_not是 filter context
比如:
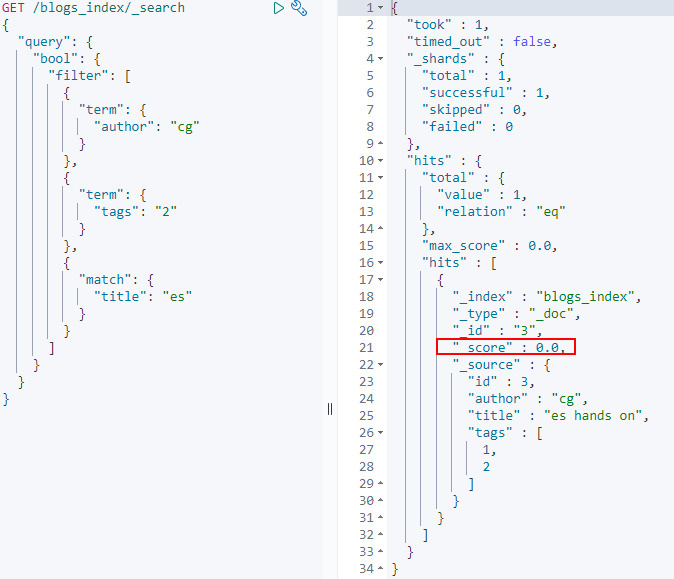
- 相当于
author = 'cg'&tag 包含 2&title的tokens 包含 'es' - 因为是filter,所以没有计算得分,score是0;如果换成must,就会有得分了。
should比较特殊,有些情况下它只影响得分,有些情况下则需要匹配:
当bool查询只包含should,则文档必须至少满足一个条件

表示field2的tokens 包含 'ok' & (field1的tokens 包含 'elephant' or 'field1的tokens 包含 'cat')
当bool查询同时也包含了must或者filter,文档不必满足should条件,但是如果满足条件,会增加相关性得分

表示field2的tokens 包含 'ok'、如果(field1的tokens 包含 'elephant'则得分更高。
当配置了minimum_should_match,则文档必须满足配置的条件个数或者百分比;
Aggregations
ES的聚合一共有4种类型

aggregations的语法结构:【注意aggregations关键字可使用aggs代替】
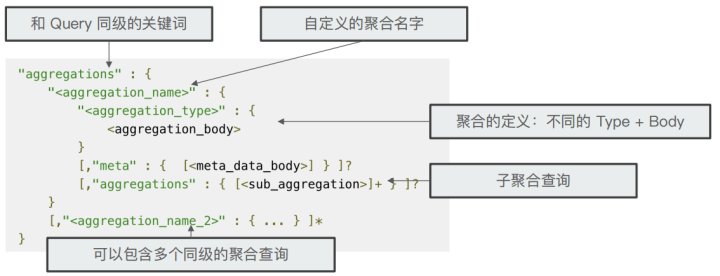
应用
最开始引入CSS是为了解决列表慢、超时的情况:
这种慢、超时的问题其实是典型问题:
- 很多大表关联;
- 表里大多数字段都要被检索,不好建索引;
- 查询方式索引用不上:find_in_set,like;
于是构建了通用的CSS方案,:
- 支持单表,多表查询(多表就融合成一个宽表索引)
- 支持一对一,一对多(nested)
能解决大部分因为数据库查询慢而引发的慢接口问题。